

不同电子资源站点所采用的请求URL格式存在差异,主要是请求URL的所提交的参数结构不同。同时,HTTP头部的其他信息结构只有内容上的不同,并没有数据结构的差异。如图3所示从CNKI下载电子资源的请求报文。
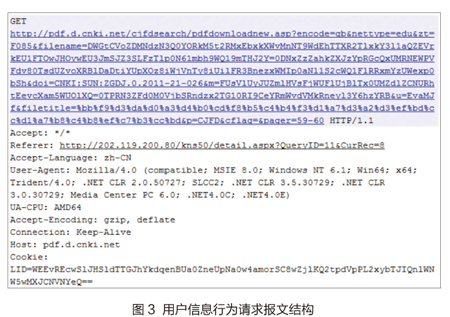
对上述报文中的起始行GET请求进行分析,可以看到该下载请求在标准的HTTP头结构上附加了几个特性化参数,如encode、nettype、doi等。针对不同电子资源的特性化下载信息,我们需要通过构建不同的文献获取行为元数据模型来进行描述。例如,针对上述CNKI用户信息行为,我们构建的用户信息行为元数据模型包含以下内容:
1.资源描述数据
包括与单次行为相关的电子资源的名称、存储名、资源类型、编码类型、所在数据库等资源描述信息。
2.用户行为数据
包括单次下载活动的源地址、目的地址、主机名、下载方式、网络类型、下载时间等行为描述信息。
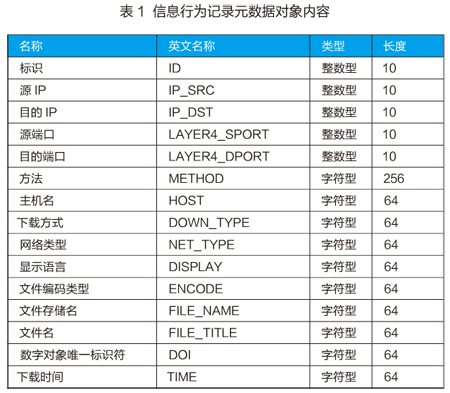
根据上述内容构建的一个信息行为记录元数据对象所包含的内容见表1。
基于JavaEE开发平台,上述内容可以很方便的以对象的形式映射到业务系统中,作为业务系统中的逻辑实体来进行管理,同时也可以将其持久化到数据库中作为数据存储和分析的基础。通过定义不同的资源元数据对象,就可以对各种类型的用户信息获取行为进行描述。
应用层特征解析处理
业务下载具有典型的时间规律,在正常作息时间内下载量较大而在无人工作的夜间采集到的下载信息较少。为了能够平滑数据采集量的大小对后台分析产生的压力,本系统采用自行设计的缓存队列分时分析算法进行载荷数据应用层特征解析处理,其算法流程图如图4所示。
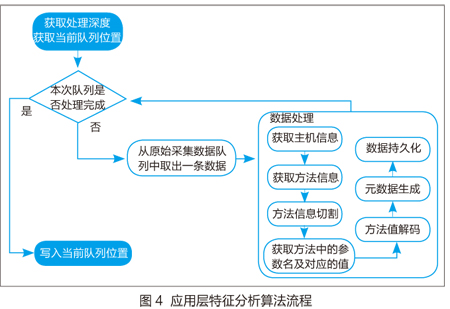
该算法的特点是在系统中以缓存队列形式存放待处理的报文信息,根据系统处理能力动态调整每个批次的处理数量,在不丢弃任何信息的基础上尽力实现报文的实时解析。
原型系统上线测试及分析
原型系统开发完成后进行了上线测试,以我校当前购置的电子资源数据库作为分析目标,系统收集的电子资源捕获类型不限于PDF,只要是电子资源站点提供的各类资源格式都可以被采集用于统计。
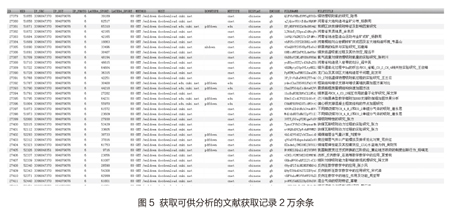
在一周的时间内,已经获取可供分析的文献获取记录2万余条,如图5所示。通过分析测试获得的数据,我们可以观察到系统按照要求对相应报文的应用层数据进行了分解,不但获取了用户下载行为的一般特征信息,如五元组信息(源IP、源端口、目的IP、目的端口、协议类型),还进一步获取了用户资源访问对象的信息,如下载文件名、文件类型、数字对象唯一标识符、文件编码类型等信息。原型系统的测试验证了本文提出的基于特征层分解的信息获取行为检测方法的可行性。
基于对图书馆用户信息行为报文的应用层特征分解,本文提出了相应的检测与分析方法,并根据该方法实现了原型系统,其特点如下:
1.对数据报文进行一次采集即可同时完成网络层数据与应用层数据的检测分析;
2.实现对用户资源利用行为的各类信息的全面获取与记录;
3.利用分布式的数据收集与处理架构在实时采集数据的基础上保障了分析能力,并可以进一步实现处理能力的动态扩充;
原型系统为开展文献获取行为计量和利用分析提供了基础平台,后续尚需在数据关联分析方面开展进一步研究,以便进一步获取用户电子资源利用行为的全景信息。
(作者单位为中国矿业大学图文信息中心)

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
数字图书馆本质就是互联网应用2015/02/03
六大组件搭建高校综合文献服务环境2014/12/09
天津市援建西藏首个县级数字图书馆投入使用2014/07/29
山东日照开放移动数字图书馆2014/07/25
秦皇岛数字图书馆落户49所中小学2014/07/25
中国数字图书馆学前教育数字图书馆山东馆启动2014/07/14
威海市高层次专家数字图书馆开通 免费提供服务2014/01/17




投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com