

Drupal是使用PHP语言编写的开源内容管理系统(CMS)和内容管理框架(CMF),曾连续多年荣获全球最佳CMS大奖。世界顶尖的前100所大学当中就有71所大学使用Drupal,国内也有不少高校在使用它建设网站。然而仅仅只是使用Drupal来建站,实在是有点大材小用,做为CMF的Drupal,有着灵活的架构和丰富的模块,通过它来构建业务系统,可以让Drupal在国内高校的“数字校园”中发挥出更大的作用,而不仅仅只是个CMS。
挑战
国内大部分高校都建成了“数字校园”,“数字校园”建设的目的是为了消除信息孤岛,所做之事简而言之就是建立公共数据交换标准和“公共数据库”,确定权威源数据以及在“公共数据库”与业务系统之间进行数据交换。具体来讲,就是通过前期调研,将“公共数据库”中业务系统需要的数据推到“中间库”中,然后由业务系统根据业务所需到“中间库”去抽取相关的数据。如果业务系统的数据被确定为权威源数据,那么该业务系统还要将其他业务系统所需的数据通过“中间库”推送到“公共数据库”中,供其他业务系统抽取。
如果想使用Drupal来构建业务系统,从而在“数字校园”中发挥更大的作用,就需要用它来构建业务系统,并使它能够与“数字校园”中的“公共数据库”之间进行数据交换,从而使其所建系统不至于成为信息孤岛。而这也正是Drupal在高校推广时遇到的最大挑战,因为Drupal并没有一个现成的解决方案可以完全满足这一颇具中国高校特色的需求。因此,笔者仔细分析了Drupal一些相关的模块,并尝试利用这些模块来解决Drupal与“公共数据库”数据交换时所遇到的部分问题。
实现
纵观“数字校园”中的业务系统,只有少量业务的数据是权威数据源,这也就意味着大多数业务系统只需要到“公共数据库”去抽取数据。因此,实现Drupal从公共数据库抽取数据的功能模块,是其构建数字校园业务系统的首要任务。
而实现这一功能,首先需要由Drupal创建业务所需的内容类型(或实体类型),然后通过相关模块将业务所需数据(大多部分都是人员和机构信息)从“中间库”取出(“中间库”中供业务系统抽取的数据是由“公共数据库”通过ODI推送过来的),在此需要注意的一点就是“中间库”中的表结构与内容类型中的字段不尽相同。这很好理解:一个是遵循学校公共的数据标准,一个是遵循具体的业务需求。本文以学生基本信息数据为例,介绍Drupal从“中间库”中抽取数据的功能模块实现方法,具体如下:
1.下载并安装相关模块
使用Drush工具下载和启用Feeds和Feeds SQL模块:drushen feeds_ui feeds_sql feeds_tamper_ui-y,这样Drush工具就会自动下载并启用Feeds、Feeds SQL和Feeds Tamper模块,同时还会下载和启用它们的依赖模块CTools和JobScheduler。
2.添加“中间库”连接信息
在Drupal的配置文件sites/default/settings.php中,添加“中间库”的连接信息,并将其DatabaseKey设置为mid:
......
$databases=array(
// 缺省数据库的连接信息
‘default’=>
array(
‘default’=>
array(
‘database’=>‘test’,
‘username’=>‘Drupal’,
‘password’=>‘Drupal’,
‘host’=>‘localhost’,
‘port’=>‘’,
‘driver’=>‘mysql’,
‘prefix’=>‘’,
),
),
//“中间库”连接信息
‘mid’=>
array(
‘default’=>
array(
‘database’=>‘mid’,
‘username’=>‘Drupal’,
‘password’=>‘Drupal’,
‘host’=>‘localhost’,
‘port’=>‘’,
‘driver’=>‘mysql’,
‘prefix’=>‘’,
),
),
);
......
3.设置内容类型
在Drupal中创建一个名为学生基本信息的内容类型,并根据需要设置其字段,如学号、姓名、姓名拼音、曾用名、英文名、身份证件类型、身份证件号、身份证件有效期、出生地码、出生日期、籍贯、血型等,并按照集成方案设置字段类型和长度。一般与“中间库”相关表的字段属性相同,以方便抽取。其中出生日期可以安装Date模块,并将其字段类型设为Date(UnixTimestamp),这样方便用户界面(UI)展示。
4.设置Feeds Importer
创建一个Feeds Importer,将其命名为“导入学生基本信息”(机器名:fi_xsjbxx),在编辑界面的Basic settings中将Attachto content type设为“学生基本信息”,并根据业务需要设置好Periodic import(一般设为every 1 day);
在Fetcher中将Fetcher从默认的HTTP Fetcher改为SQLfetcher,并将SQL fetcher设置中的Database勾选为“中间库”的“mid”;
在Parser中将Parser改选为SQL parser,并将SQL parser设置中的Database选为“mid”,在SQL query文本框中填入SQL语句:SELECT*FROM GXXS_XSJBSJZL(其中GXXS_XSJBSJZL为“公共数据库”同步到“中间库”的学生基本数据子类表名,这里为了方便起见,所以使用了通配符*,一般的用法是需要用到什么字段,就填入什么字段),如果SQL语句没有出现错误的话,会在下面显示测试信息,会显示执行SQL语句后记录总数和字段数,并有个表格显示记录内容,以便判断在SQL query文本框中所输入SQL语句是否正确;
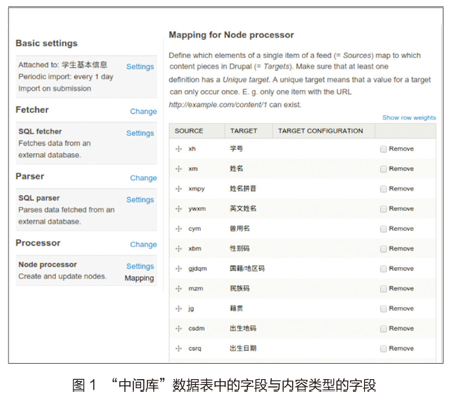
在Processor中将Processor设为默认的Node Processor,并将其设置中的Bundle选为“学生基本信息”,将Update existingnodes选为“Update existing nodes”,Text format保持默认的“Plain Text”,Expire nodes保持默认的“after 1 day”;接下来就是最关键的一步了,在Processor中点击Node Processor中的Mapping,将“中间库”数据表中的字段与内容类型的字段一一对应起来,如图1所示。
5.设置Feeds Tamper
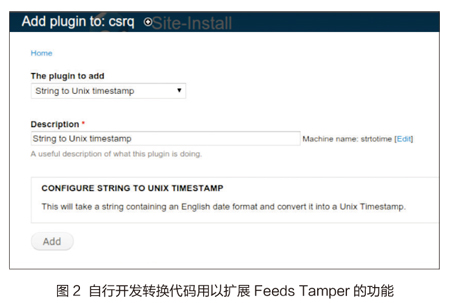
在完成了上述配置之后,基于Drupal的业务系统就差不多可以正常地从“中间库”抽取公共数据了,但这之前还需要做一个小处理。“中间库”的出生日期根据部标是8位字符,而为了UI展示,在前面Drupal内容类型的字段类型的设置时,是建议安装Date模块并将字段类型设为Date(Unix Timestamp)的,这就意味着在抽取过来的数据需要在做“一个字符串到时间戳”的转换之后,才能够保存到Drupal中,因此需要用到FeedsTamper模块,可以选择TAMPER标签页,并找到出生日期这个Mapping,然后点击Add Plugin,将The plugin to add标签下的单选框选为“String to Unix Timestamp”,这样就可以在抽取出生日期时将部标的8位字符串转换成Date(Unix Timestamp)类型保存在Drupal中。而且由于Feeds Tamper是插件式的,还可以自行开发转换代码用以扩展Feeds Tamper的功能。其设置如图2所示。
通过上面的配置,基于Drupal构建的业务系统就可以从外库“中间库”抽取所需的数据了,上述三个模块相互配合就很方便地完成了数据抽取功能,而这么复杂的功能,需要用户做的事情却并不多,不得不让人感叹Drupal及其模块的强大。
不足
然而,由于目前国内高校“公共数据库”从业务系统抽取数据的方式比较单一,基本都是基于数据库层面来进行的。因此Drupal要融入数字校园就还必须要有一套比较成熟的将数据输出到外部数据库的解决方案。令人遗憾的是,Drupal虽然有着一套较为成熟的数据输出解决方案,但却是基于WebService的。基于数据库层面上的数据输出,虽然也有一些模块支持,但还不能形成一个比较成熟的解决方案。
综上所述,要想进一步推动Drupal在我国高校的发展,就需要解决其与“公共数据库”的数据交换问题。好在Drupal不仅是一个CMS,还是一个CMF,可以很灵活地通过编写一些功能模块,来满足某些功能需求。笔者和高教学会信息化分会Drupal推进组的同仁们,正在着手编写DataHub数据交换模块,尝试通过这个模块来实现符合国人思维习惯,并能在数据库层面进行数据交换,以期解决Drupal与外部数据库的数据双向交换问题,从而进一步加快Drupal在我国高校的推广。
(作者单位为温州大学现代教育技术中心)

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
使用Drupal做的网站:国内大学2015/05/27
那些国外大学使用Drupal的网站2015/05/27
那些用Drupal做的大学网站2015/05/20
中国政法大学:基于Drupal构建研究院院网2015/05/20
Drupal是怎样帮高校改善网站体验的?2015/05/20
Drupal的过去、现在以及未来2015/05/19
Drupal在高校2015/05/19




投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com