

预算<20 万?普通高校部署DeepSeek攻略
2025-02-24 中国教育网络-微信公众号
作为当下大模型领域的“新晋顶流”,DeepSeek凭借其在开源免费商用授权、本地化部署能力等的独特优势,一经发布便火爆全网,在众多行业领域内掀起惊涛骇浪。教育行业也不例外,高校部署DeepSeek大模型已成为提升教学科研能力的重要举措。
目前,国内众多知名院校已完成了DeepSeek的本地化部署工作;而部分高校却囿于科研资源有限、技术团队规模小、数据隐私要求高等困境,或处于观望状态,或困难重重、进展受阻。那么,普通高校如何基于有限预算和资源,进行DeepSeek的本地化部署?学校在着手部署前都需要考虑和规划哪些方面内容?
本文基于行业实践数据,从基础部署框架、运行中的成本优化、典型成本对比和风险应对预案等维度提出部署,以期为普通高校提供具有价值的部署参考。
一起来看——
低成本部署框架
要想低成本实现大模型本地化部署,三大核心内容不可或缺:硬件的选择、模型优化的关键技术和开源生态的利用,以下基础部署框架和相应策略:
硬件选择
通过“旧设备改造+智能调度+云端备用”的组合拳,高校既能节省硬件采购费,又能应对突发需求。通过本地设备+云端资源,实现成本与效率的最佳平衡。
1.存量利用,旧设备变废为宝:在部署DeepSeek之前,高校应首先对现有的硬件资源进行全面的评估与整合,避免不必要的重复投资。优先整合校内现有GPU服务器(如NVIDIA T4/P40等),或改造实验室游戏显卡(如RTX 3090/4090),通过NVIDIA驱动解锁CUDA计算能力。
2.混合算力池,智能调度资源:使用KubeFlow或Slurm搭建异构计算集群,整合CPU/GPU节点实现分布式推理。
说明:
KubeFlow:相当于“AI任务调度中心”,自动分配任务到合适的硬件(如把简单作业派给CPU,复杂计算派给GPU)。
Slurm:扮演“计算资源管家”,协调多台服务器的协作(如同让10台电脑合力完成1个大型作业)。
3.云端弹性计算,用“共享充电宝”模式:阿里云/腾讯云「教育扶持计划」申请免费算力券,突发性需求使用竞价实例(价格低至按需实例1/3)。
说明:
免费算力券:阿里云/腾讯云给高校的“算力代金券”,相当于每年免费领取100小时云服务器使用权。
竞价实例:夜间或节假日以1/3价格租用闲置云资源。
模型优化关键技术
1.量化压缩,给AI模型“瘦身”:可以应用8-bit/4-bit量化(如GPTQ算法)将模型体积压缩60%~75%,使用llama.cpp等框架实现CPU推理。
说明:
8-bit/4-bit量化:将模型参数从“精确到小数点后4位”简化为“保留整数”;
GPTQ算法:智能选择最重要的参数保留精度;
llama.cpp框架:让压缩后的模型能在普通电脑CPU上运行。
2.知识蒸馏,大模型带小模型:用DeepSeek-Lite等轻量架构(参数量<10B)继承DeepSeek原模型70%+能力。
3.动态卸载,智能内存管家:通过HuggingFace的accelerate库实现显存-内存-硬盘三级存储切换。
类比说明:
accelerate库功能包括:
自动搬运工:当显存不足时,把暂时不用的模型组件移到内存;
智能预加载:检测到教师登录系统时,提前加载批改作业模块。
开源生态利用
1.模型版本:DeepSeek-R1有社区版和商业版,建议采用社区版(Apache 2.0协议)替代商业版本。
表1 DeepSeek-R1社区版和商业版对比
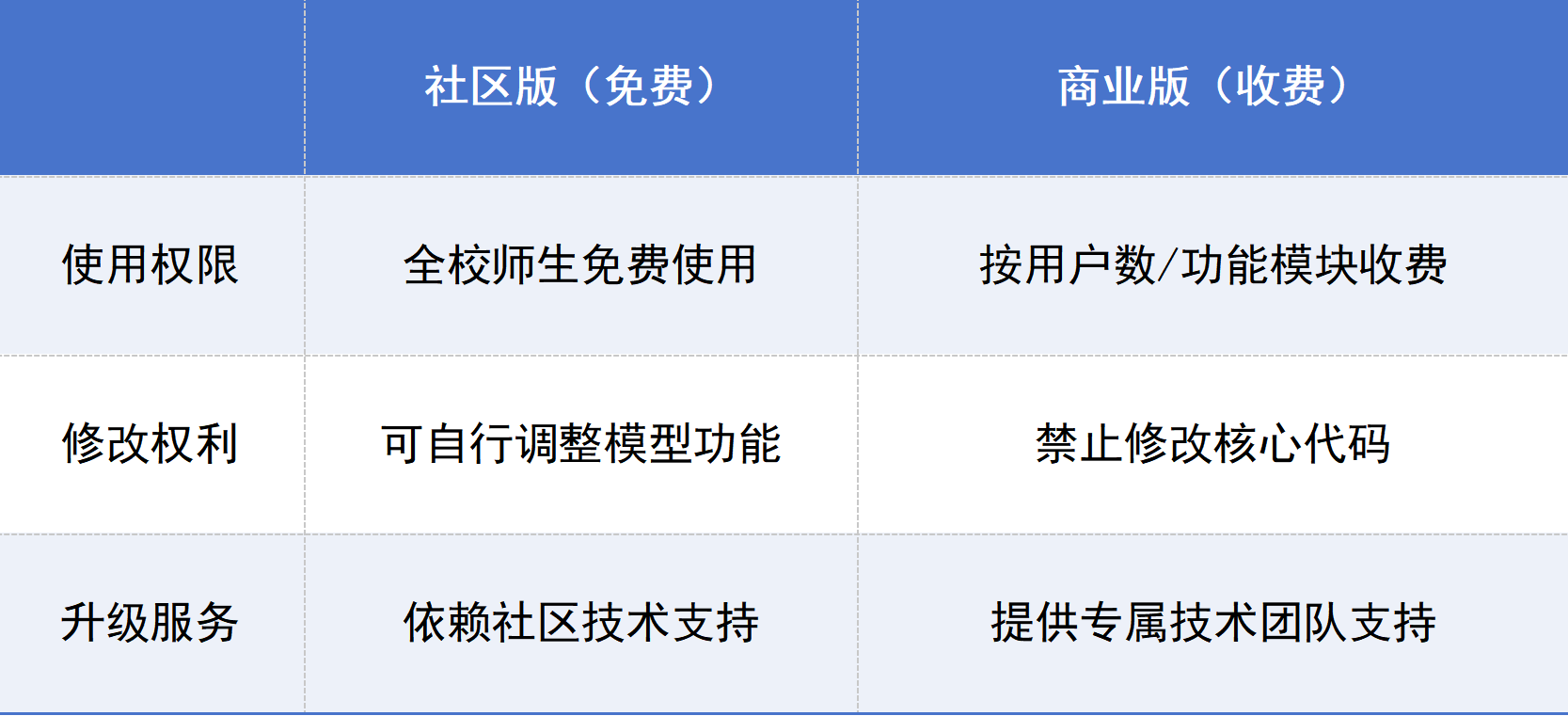
2.工具链:MLOps使用开源方案(MLflow+Airflow+DVC),替代Azure ML等商业平台。
运行成本优化方案
在了解了基础的部署框架后,学校的本地化部署还将面临场地、服务器、算力、数据量、运行、能耗和可持续运行等诸多因素,如何在后续运行中进一步优化成本?让部署从“高投入项目”转变为“可持续生态”,真正实现“花小钱办大事”?以下为一些建议:
算力众筹网络
搭建BOINC式分布式计算平台,将教学机房空闲时段算力(课表编排后凌晨1-5点)用于模型微调。
类比说明:
课表编排算力:教学机房凌晨1-5点变身“AI计算工厂”,如同深夜利用空置教室开自习室
分布式计算平台:把100台学生电脑连成“超级计算机”,处理模型微调任务
联盟学习机制
与兄弟院校共建模型联盟,各节点使用本地数据训练后加密交换梯度参数,解决单一机构数据不足问题。
能耗优化
在生物/化学实验室共享液冷系统,使GPU集群PUE值(?PUE值是评价数据中心能源效率的指标,表示数据中心消耗的所有能源与IT负载消耗的能源之比?)从1.5降至1.1。
使用RAPL(Running Average Power Limit)动态调整CPU功耗。
类比说明:
共享实验室设备:利用生物实验室的循环水冷装置
RAPL技术:根据任务量自动调节CPU功耗,如同手机根据亮度调节耗电
可持续运营体系
1.人才培养闭环
开设《大模型工程化》实践课,将模型维护作为毕业设计课题,形成「高年级维护系统-低年级使用系统」的自治生态。
2.产学研联动
与地方企业共建联合实验室,企业提供旧显卡(如退役的A100 40G),学校提供算法优化服务。
3.成本监控仪表盘
部署Prometheus+Grafana监控体系,实时显示每千次推理的电力/算力成本,设置自动熔断阈值。
典型方案成本对比
地方高校部署DeepSeek-R1大模型常有本地集群、云端方案和混合联邦方案三种典型方案:
表2 典型部署方案成本对比表
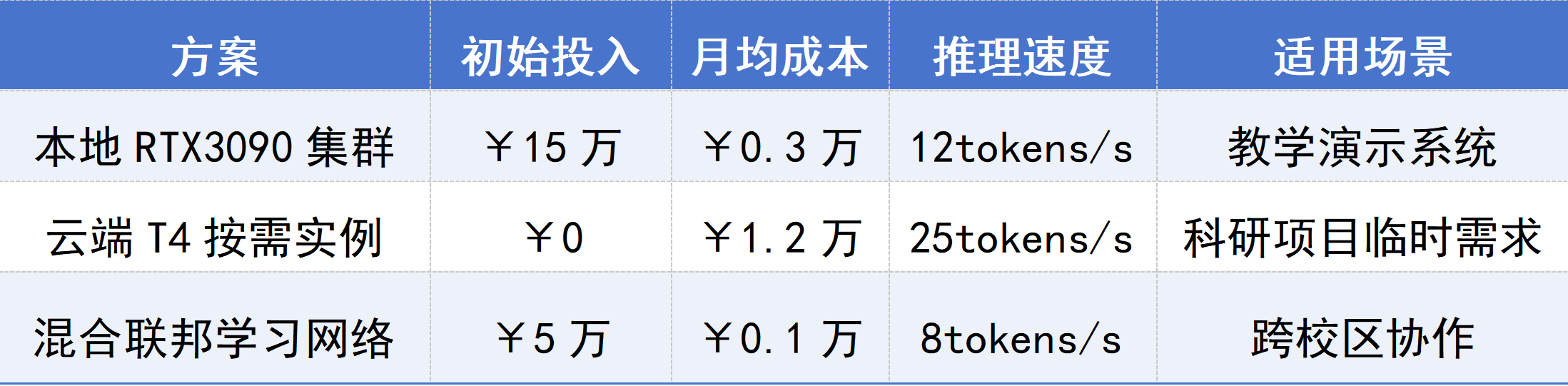
本地集群具有15万元初始投入但运维成本最低(0.3万/月),适合长期教学系统建设;
云端方案零初始投入但月费较高(1.2万),凭借25tokens/s的较快推理速度,适用于科研项目的弹性算力需求;
混合联邦方案以折中的5万初始投入和最低月费(0.1万),通过8tokens/s的协作效率满足跨校区场景需求。
因此高校在部署时需要权衡前期投入、持续成本与场景适配度,综合考虑选择最适配自身的方案。
风险应对预案
考虑到本地化部署过程中可能会面临显存泄漏、模型泄露、突发负载等风险,需要提前做好预案进行有效规避:
1.显存泄漏:给AI系统装“健康手环”,部署NVIDIA的DCGM监控模块(可实时监测显存使用率),设置自动重启阈值。
2.模型泄露:给数据上“防弹保险箱”,使用Intel SGX加密推理容器,内存数据全程加密。
类比说明:
Intel SGX加密容器:构建“数据保险箱”,即使服务器被入侵,模型也像锁在钛合金盒子里;
内存加密技术:数据使用时自动解密,处理完立即重新加密
3.突发负载:配置“弹性伸缩弹簧”,配置AutoScaling策略,当请求队列>50时自动启用AWS Lambda无服务器计算。
类比说明:
AutoScaling策略:设置“智能服务员”,当排队超过50人(请求队列>50),自动呼叫云端支援;
AWS Lambda无服务器计算:云端临时工模式,用多少算力付多少钱
综上所述,通过上述方法,高校可在年运维预算<20万元的条件下构建支持200人并发使用的智能计算平台,建议从「课程辅助智能体」等轻量场景切入,逐步扩展至科研支持系统。
如您对DeepSeek的本地化部署还有更好建议,或对此有兴趣,欢迎联系我们,提供指导、共同交流

联系人:闻老师
申请好友时请务必说明单位和姓名
注:DeepSeek对本文有帮助,文内数据仅供参考
监制:余兴真
技术指导:曾君平
编辑:建乐乐

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
相关阅读
一文汇总!15所高校DeepSeek部署最新进展2025/02/20
兰大DeepSeek-R1,满血登场!!2025/02/24
电子科大×DeepSeek!开学首日满血上线!2025/02/24
中兴通讯参与打造智海AI教育一体机 携手DeepSeek助力人工智能教育2025/02/11
兰大DeepSeek-R1,满血登场!!2025/02/24
电子科大×DeepSeek!开学首日满血上线!2025/02/24
中兴通讯参与打造智海AI教育一体机 携手DeepSeek助力人工智能教育2025/02/11

一起关注互联网发展、互联网技术、互联网体系结构……

在教育部科技司领导下,中央电化教育馆组织实施了教育信息化教学应用实践共同体项目...

工作要点聚焦:教育信息化、网络安全……都怎么干?

投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com