

李星:IPv6在AI和大模型背景下如何加速演进
2024-07-17 中国教育网络

李星 CERNET网络中心副主任、清华大学教授
科技发展的历史演进
从历史的演进看科技行业的发展,可以发现一些有趣的事实。20世纪60年代的新兴产业是半导体集成电路,如英特尔公司。70年代在芯片的基础上,构建出个人计算机系统,出现了苹果、微软等公司。80年代,互联网基础设施把电脑连接在一起,以思科、戴尔等公司为代表。90年代,进入了互联网服务时代,亚马逊、雅虎风靡一时。2000年以后是应用程序的天下,YouTube、Facebook诞生。2010年起,移动互联网兴起,就出现了Telegram、Twitter等公司。2020年后,人工智能逐渐发展并应用, OpenAI横空出世。

图1 科技发展的历史演进
人工智能的方法论
OpenAI的方法论建立在几个重要的原理上,这几个原理包括“苦涩的教训(The bitter lesson)”、扩展定律(Scaling Law)和涌现(Emergence)。
“苦涩的教训(The bitter lesson)”这一说法源自机器学习先驱理查德·萨顿(Richard Sutton)在2019年发表的一篇经典文章。通过探讨人工智能近十几年走过的弯路,文章表示,人工智能之所以取得显著进步,所依赖的并非知识,而是算力、搜索和学习(Search and Learning)。
过去,研究人员试图让人工智能按照人类的思维方式进行运作(通过将知识硬编码到系统中),但这种方法行不通。相反,对人工智能的研究应该使用能够发现和捕捉外部世界无穷复杂性的通用方法,也就是搜索和学习。换句话说,要让人工智能体(AI Agent)能够像人类一样发现新事物,而非重新找到人类所发现的内容。萨顿指出,如果想让人工智能长期获得提升,利用强大的算力才是王道。这里的算力隐含了大量的训练数据和大模型。
扩展定律(Scaling Law)指的是,随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高,并且为了获得最佳性能,所有三个因素必须同时放大。当不受其他两个因素的制约时,模型性能与每个单独的因素都有幂律关系。
因此,当计算量固定(比如固定要进行n次浮点计算),而数据规模和模型参数量不固定时,性价比最高的计算方式就是训练大模型,而非小模型(即使大模型最终到不了收敛状态而小模型能收敛)。当计算量增大时,最高效的训练方式是用大模型提高批量大小(batch size),并且相应地扩大少量数据。
涌现(Emergence)通俗地讲,就是量变引起质变。从1953年雷蒙德·钱德勒(Raymond Chandler)所著小说《漫长的告别》(The Long Goodbye)中,我们可以一窥涌现的真相:“如果一个人只是偶尔喝大,他仍和清醒的时候是一个人。然而一个酒鬼,一个真正的酒鬼,喝醉了就完全成了另一个人。你无法预料他会做出什么事情,唯一确定的是,他已经不是你之前认识的那个人了。”
如果说原子论挖地三尺,力图寻找世界最基础的“砖瓦”;涌现论则将目光投向上方和外部,考察当事物变得足够大、足够复杂时,是否会有新奇的现象突然出现。
人工智能和互联网的设计原理
通过人工智能领域的“苦涩的教训”、扩展定律和涌现这三大原理,我们能够发现,那些能够充分发挥计算力的通用方法,最终能够取得显著的成功。这一现象背后的驱动力是摩尔定律,即计算成本的持续指数级下降。对于互联网领域和人工智能领域,这一定律都成立。
让我们来回顾互联网的基本原则,那就是主机不必信任网络,所以网络不必完美(也不可能完美)。为了达到通信的目的,网络传输“尽力而为”,其他功能由“端对端”完成。
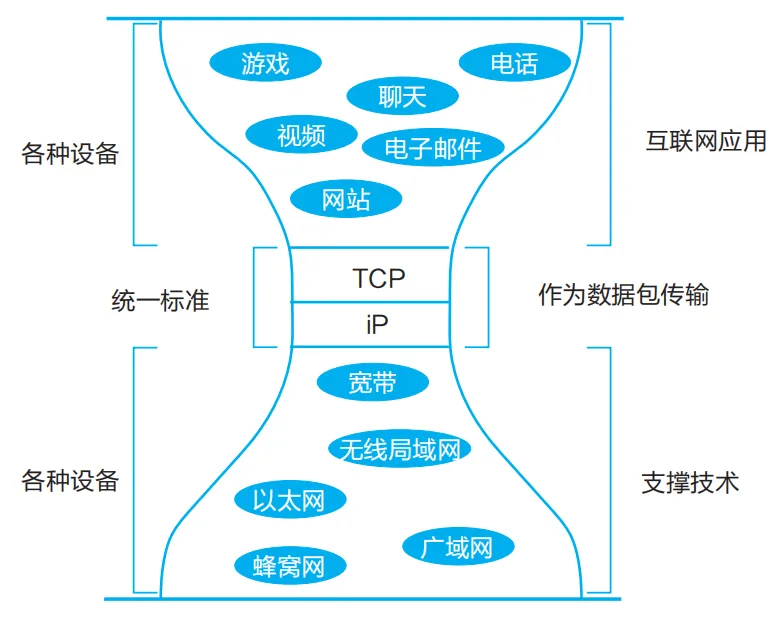
图2 互联网沙漏模型的类比
从互联网的基本原则到人工智能基本原理,里面似乎有相通的地方。找到了正确的方法,技术的发展就会一日千里,突飞猛进。
一直以来,互联网技术的发展都受到了IETF等各种组织的推动。在互联网时代,互联网工程任务组(IETF)是开放的代表,其主要任务是进行技术治理,以确保互联网的互操作性。IETF主要产出各类标准,遵循开放参与、流程透明、公开发表和免费使用的原则。这种始终如一的开放性规则,促进了互联网软硬件创新的飞速发展。
然而,生成式人工智能具备比TCP/IP更强大的功能,却尚未出现IETF这样的组织。
目前,科技公司对大模型有两种开发方式:一种是开源,另一种是闭源。但许多声称开源的人工智能模型,在数据和训练方法上并不透明,无法满足真正的科学研究需求。这种“开源洗白”(open-washing)的现象严重阻碍了科学的可重复性和创新。
通过对多种模型的详细评估,研究机构列出了模型开放性排行榜,揭示了当前人工智能开源的现状。尤其值得关注的是,一些小型公司和研究团队在有限资源下,反而表现出更高的透明度和开放性。

图3 模型开放性排行榜
在生成式人工智能时代,真正的开源不仅是代码的开放,更是数据、训练方法和模型细节的全面开放和透明。这不仅是为了科学的进步,也是为了确保人工智能技术在社会中的负责任应用。
如果在人工智能领域,也能成立类似IETF的全球性技术组织,那就能将世界各国联结起来,共同推动创新,开发出激动人心的新技术。
没有互联网就没有ChatGPT
许多伟大事物的诞生都没有蓝图,它们的出现并非出于某个人的远见,甚至不在计划之中。美国互联网先驱者、ICANN前任主席史蒂芬·克罗克(Steve Crocker)曾表示,人工智能和网络是一粒种子孕育出的两颗美味的果实(Sweet Fruits from One Seed: AI & Networking)。
2013年美国出版的科技评论著作《我们最后的发明》(Our Final Invention)探讨了不顾一切地追求先进的人工智能技术的危险。书中有这么一句话:“任何情况下都不得把ASI(意为人工智能)的超级电脑接入网络。”科学家认为,一旦人工智能达到人类水平,它将拥有与人类一样的生存动力。人类可能会被迫与比想象中更狡猾、更强大、更陌生的对手竞争。
但是,ChatGPT之所以成功,就是接入了互联网,使用了大量的数据进行训练。可以说,没有互联网就不会有ChatGPT。
虽然人工智能诞生于互联网,但它也给互联网带来了一系列挑战。第一个挑战是对网络性能提出了更高的要求,目前的分布式训练对于丢包率、传输带宽和延时极其苛刻。第二个挑战是造成了互联网的分裂,即按IP地址区分服务区。比如报道称7月9日起,OpenAI将采取额外措施,停止来自不在OpenAI支持的国家、地区名单上的API(应用程序编程接口)使用。第三个挑战是趋中心化。大模型都来自超级大公司,而互联网的本质是分布式的,趋中心化则会造成风险。第四个挑战是可信。例如,怎样判断是合法模型的“幻觉”,还是黑客攻击?
人工智能也将给世界带来新的分裂。互联网之父温顿·瑟夫(Vint Cerf)曾总结了互联网的三大分裂:一是技术性分裂,二是政治性分裂,三是商业性分裂。人工智能出现后,还将导致分布、可信、算力、算法等分裂。
人工智能时代,IPv6的创新
要创新一定要有所不同,必须有新的想法。如果循规蹈矩、按照现有思路,一定无法成功。举个例子,我们清华大学团队发明的IVI技术(无状态的翻译过渡技术),就是在否定了IPv6双栈过渡方案的基础上进行的重要创新,正是由于当时的大胆和超前部署,使我们国家在IPv6方面走得比世界上任何一个国家都要远。这样的精神在人工智能时代依然很有价值。
回顾与IPv6的历史渊源,可以追溯到1994年。当时,我参与了中国教育与科研计算机网CERNET的设计工作。1998年,我们开始建设IPv6 over IPv4。2000年,我们建设了中国下一代互联网交换中心DRAGONTAP,研制国家自然基金联合重大项目“中国高速互联研究试验网NSFCNET”。2004年,我们建设了CERNET2。在网络路线上,CERNET2选择了建纯的IPv6网络,这在当时是非常大胆的设计。
2007年,清华大学团队发明了无状态的翻译过渡技术——IVI。在罗马数字里,IV是4,VI是6,IVI即代表IPv4和IPv6的互联互通。有了IVI技术,就可以逐步从IPv4向IPv6转移,既可以实现服务,也可以与IPv4完全互通,从而新建纯IPv6网络,并逐渐将现有的IPv4用户转移到IPv6上,用户可在不知不觉中实现过渡。
在人工智能时代,IPv6的应用空间更加宽广了,可以为机器人联网。其实最初,在推广IPv6时,大家一直在寻找IPv6的“杀手级应用”。起初认为,在线视频和物联网可能是IPv6的杀手级应用,但后来发现,IPv4也可以满足这些需求。所以,IPv6的杀手级应用到底是什么?我们在做IPv4/IPv6无状态翻译过渡技术IVI时,提出与IPv4互联互通才是IPv6的杀手级应用。现在我觉得,还应该加上机器人联网(甚至是神经元联网),也就是人工智能之间的相连,这应该也是IPv6的杀手级应用。
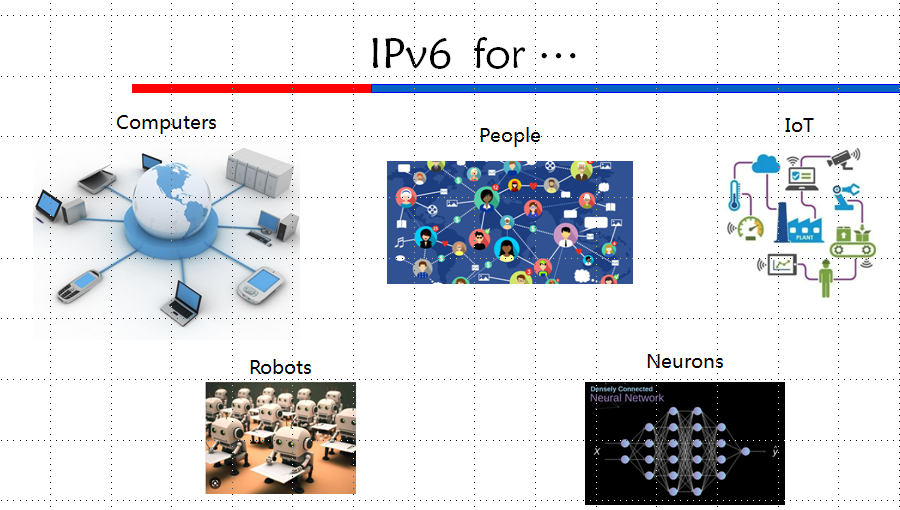
图4 IPv6的各种应用场景
那么,人工智能究竟是工具的革命,还是革命的工具?如果我们在互联网的各个层都引入人工智能的方法,来提高网络的可管理性和安全性,这是工具的革命。而当人和网络之间增加了人工智能时,那么人工智能就成为了革命的工具。
在人工智能时代,IPv6和生成式人工智能将相互依赖、互相促进。生成式人工智能需要IPv6的支撑;同时,生成式人工智能也会给IPv6带来新的机遇。
未来将是什么?
今年是中国接入互联网的30周年。30年是一个轮回。
在30年前,互联网刚进入中国之时,我们这一代人曾经面临过一些普遍的难题。在互联网的应用方面,我们国家当时jpeg是硕士生的论文;而世界上jpeg的源程序已经可以从互联网上免费下载。在设备方面,前期我们受到了“巴统”(巴黎统筹委员会是对社会主义国家实行禁运和贸易限制的国际组织)的限制;后期,“巴统”取消了,中国可以进口世界上最先进的路由器等网络设备。我们在CERNET2上采用国产和进口混合组网,极大地促进了国产路由器厂商的技术进步。
而当前,我们又面临着一些普遍的难题:在ChatGPT的应用方面,中国主流社团仍然是传统的编程方式和传统科学研究的方式,而世界发达国家开始用ChatGPT自动生成程序,利用人工智能对新材料、生物技术、制药技术等进行创新性的研究。在设备方面,地缘政治博弈导致了中国高科技设备的进口受阻。
这一代人工智能正如最初互联网出现时,具有强大的、可以变革整个社会的力量,我们如何抓住这个历史关键发展时期的机遇?如何应对它正在带来的具有颠覆性力量的挑战?我们正站在历史发展的十字路口上,需要作出正确的决策。
互联网发展至今已有五十五年,从诞生之日起,它就在一步一步演进。从设计和演进来看,互联网最开始需要人类强参与,后来变为人类弱参与,未来可能演进为不需要人类参与。
基于稳定的互联网体系结构和设计原则,互联网的核心技术模块一步一步演进。以十年为一个周期,在互联网的不同发展阶段,有着不同的代表性技术热点。
1970年代,最重要的技术是ARPANET早期使用的NCP。1980年代,最重要的技术是TCP/IP。1990年代,是DNS和BGP4。2000年代,WWW出现,最重要的技术则是HTTP。2010年代,因受互联网商业化和斯诺登事件影响,加密的HTTPS广受关注。
那么,2020年代最具代表性的技术热点是什么?是IPv6与人工智能的结合吗?这有待我们的进一步探索。
本文根据CERNET网络中心副主任、清华大学李星教授在2024年IPv6创新发展大会分论坛上的报告整理
责编:陈茜

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
相关阅读
新书速递!清华大学李星教授新著《新一代IPv6过渡技术——IPv6单栈和IPv4即服务》2024/07/15
李星:人工智能之于高等教育,其意义如同现代大学的诞生2024/04/02
李星:互联网治理要回归互联网本质2024/01/09
李星:互联网技术的演进历史与启示2024/03/05
李星:从互联网的发展看人工智能的治理与创新2023/11/10
李星:纯IPv6的演进和创新之路2022/09/06
骄傲!清华大学李星教授入选互联网名人堂2021/12/14
李星:互联网技术和教育信息化的历史与未来2021/02/02
李星:人工智能之于高等教育,其意义如同现代大学的诞生2024/04/02
李星:互联网治理要回归互联网本质2024/01/09
李星:互联网技术的演进历史与启示2024/03/05
李星:从互联网的发展看人工智能的治理与创新2023/11/10
李星:纯IPv6的演进和创新之路2022/09/06
骄傲!清华大学李星教授入选互联网名人堂2021/12/14
李星:互联网技术和教育信息化的历史与未来2021/02/02

一起关注互联网发展、互联网技术、互联网体系结构……

在教育部科技司领导下,中央电化教育馆组织实施了教育信息化教学应用实践共同体项目...

工作要点聚焦:教育信息化、网络安全……都怎么干?

投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com