

垃圾邮件过滤的性能是用户最关心的问题。实际上,邮件过滤系统的性能评测包括过滤有效性及过滤效率的评测,是检验过滤算法的有效性和过滤系统效率的重要依据。
性能评测是一个复杂的过程,包括评测指标的确定,评测数据的选择,以及评测环境的构建等。本文主要介绍目前垃圾过滤的性能评测的基本方法,并以华南理工大学信息网络工程研究中心暨广东省计算机网络重点实验室联合广州数园网络有限公司研发的智能邮件处理系统Matrix为例来说明相关的性能指标参数。
评测指标
评价垃圾信息过滤器的标准有很多种,其中最常用的是召回率和准确率。然而对于评价邮件过滤系统在线与处理学习来说,目前最通用的是国际文本信息检索会议(Text Retrieval Conference,TREC)垃圾邮件过滤竞赛中的评价方法。该方法将评价指标分为基本评价指标和过滤器的操作特征指标两类。
评价垃圾邮件过滤系统性能的基本指标有两个:
1.正常邮件的误过滤率(ham misclassification percentage,简写hm%),即被误识别为垃圾邮件的正常邮件占所有正常邮件的比例;
2.垃圾邮件的误过滤率(spam misclassification percentage,简写sm%),即被误识别为正常邮件的垃圾邮件占所有垃圾邮件的比例。
要使得一个过滤器具有更好的使用效果,应该尽可能的最小化这两个误过滤参数值。然而,由于一个指标的提高往往以牺牲另一个指标为代价,因此同时最小化这两个误过滤参数值一般来说是不可能的。因此在实际评测时,往往使用如下的操作特性指标作为过滤有效性的评测指标。
过滤器操作特型指标的原理可以叙述如下:给定一个概率阈值,当某条信息是垃圾信息的概率超过时就认为它是垃圾信息,否则认为该信息为正常信息。显然,阈值的增加会减少正常邮件的误过滤率,但同时也会增加垃圾邮件的误过滤率;反之亦然。因此,可以表示为的函数,也就是说,当给定阈值时,可以根据值计算出。该函数相应的曲线图被称为受试人操作特征曲线图(Receiver Operating Characteristic,简称ROC)。ROC曲线以下部分表示基于所有可能阈值而获得的一个综合评测标准,其统计意义为:一个正常邮件比一个垃圾邮件具有较低评测值的概率。为了保持与失效性能指标和的一致性,将ROC曲线之上的部分称之为失效比率,即比率。
基于正常邮件和垃圾邮件的误过滤率,本文还使用了在TREC垃圾邮件过滤竞赛中的过滤器性能评价指标--逻辑平均误过滤率。
这描述了正常邮件和垃圾邮件的误过滤比率的几何意义。它并没有事先假定正常邮件和垃圾邮件误过滤率的相对重要性,而是根据二者的比例设定相应的权重参数。
除了和这两个基于阈值的评价指标外,考虑到<hm%,sm%>的统计数值,通常还将(简写为h=.1)时对应的数值对作为衡量过滤器整体性能的一个参考指标。
过滤器的实际性能和用户的期望在过滤器工作期间可能不断地发生变化。即,过滤器的性能可能得到提高或下降。为此,TREC垃圾邮件过滤竞赛采用了两种描述过滤器学习曲线的方法:1.分段近似法(piecewise approximation )和逻辑回归法(logistic regression),该方法将和表示为已处理邮件数的函数;2.将描述为已处理邮件数的一个函数。
评测数据集
国际文本信息检索会议TREC会议于2005年开始举办垃圾邮件过滤测评,由Waterloo大学的Gordon V. Cormack教授负责组织,每年吸引了世界多支队伍参加。TREC垃圾邮件过滤竞赛的目标是为全球垃圾邮件的研究人员和组织提供一个交流的平台。TREC 2007公开数据集来自从2007年4月8日至7月6日期间发送到一台实际邮件服务器上的全部邮件。在该邮件服务器上存在多个已经停用但仍然继续接收垃圾邮件的账户,同时设立了多个蜜罐账号。所接收的邮件经DMC、Bogofilter等几种机器学习方法和人工判别后形成最终公开发布的数据集。
国内于2007年在全国搜索引擎和网上信息挖掘学术研讨会(Search Engine & Web Mining, SEWM)上首次增加了垃圾邮件过滤评测项目。评测的目标是通过提供一个以中文为主并反映最新垃圾邮件特征的大规模邮件数据集,并以此检验各种过滤技术在实际垃圾邮件过滤中的有效性。该评测目前由华南理工大学广东省计算机网络重点实验室主持。
SEWM 2007垃圾邮件评测数据集的构成主要分为公开和私有数据集两部分。其中公开数据集共60000封(垃圾邮件45000封,正常邮件15000封)提供给测评参与单位作为训练、测试或者添加到本地的垃圾邮件库,而私有数据集共75506封(垃圾邮件60000封,正常邮件15506封)作为测评主办方主要评测标准。私有数据集在评测结束后全部公开。SEWM2008的公开数据集包括70000封邮件,而私有数据集的垃圾与正常邮件共99046封。在数据集的准备方式上,SEWM2008与2007相似,但反映了更新的垃圾邮件特征。
SEWM垃圾邮件评测的数据集全部来自Matrix所处的真实邮件处理环境,经过人工抽样检查并于其他公开垃圾邮件样本集进行对照后挑选得到。正常邮件来源于以下几个方面:
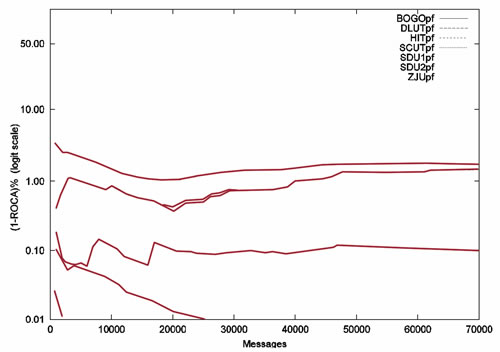
图1 Matrix在TREC 2007公开数据集上的(1-ROCA)%曲线
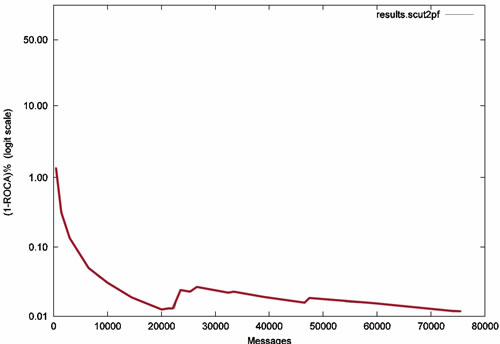
图2 Matrix在SEWM 2008公开数据集上的(1-ROCA)%曲线
1.项目组人员自发提供的实际私人邮件;
2.公开邮件群发送的实际邮件;
3.按照实际私人邮件和公开邮件的主题、词频、附件等分布特征,通过Internet抓取到邮件内容合成的电子邮件。
在结构上,SEWM的垃圾邮件数据集以中文为主,同时也包括了部分英文邮件。数据集中的垃圾邮件都为真实垃圾邮件,而正常邮件则以网络抓取为主,并加入部分真实的私人邮件。最后,对两种类型的邮件做平行化处理得到最终的数据集。
评测结果示例
对Matrix的过滤器使用了TREC 2007的公开数据集评测,该数据集共有正常邮件25220封,垃圾邮件50199封,合计75419封邮件。其中过滤器SCUT2pf对正常邮件的分类准确率为99.71%,对垃圾邮件的正确判断率为99.84%,亦即25220封正常邮件中只有74封正常邮件被判为垃圾邮件,而50199封垃圾邮件中只有79封垃圾邮件未被检测出来,相应的(1-ROCA)%曲线如图1所示。
SEWM 2008公开数据集共有70000封邮件,其中正常邮件20000封,垃圾邮件50000封。Matrix对正常邮件的准确率为99.935%,对垃圾邮件的准确率为99.98%。相应的(1-ROCA)%曲线如图2所示。具体的评测结果及其说明参见http://www.scut.edu.cn/ccnl/antispam/。
垃圾邮件过滤系统的评测方法是一个不断变化的过程。性能和准确率是评价一个垃圾邮件过滤系统的最重要的两项指标。由于实际的邮件系统往往每小时要处理几万、几十万甚至上百万的邮件,而大部分垃圾邮件过滤方法目前具有这相近的准确率,因此与准确率相比性能评价将是未来邮件过滤系统评测系统更加需要努力的方向。未来的垃圾邮件过滤评测将增加数据集的规模,同时采取技术手段使评测过程与实际邮件处理系统更加接近。
(作者单位为华南理工大学信息网络工程研究中心)
《中国教育网络》2008年6月刊

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
对抗垃圾邮件2012/05/16
印度成垃圾邮件最大来源地2012/01/04
韩国拟通过封堵25端口打击垃圾邮件2011/11/29
挑选反垃圾邮件的8个建议2011/06/28
垃圾邮件引愤怒美一男子切断电缆被捕2011/06/03
全球垃圾邮件骤减 未来或将转移到社交网络2011/01/12
卡巴斯基实验室披露:五大垃圾邮件发送国家2011/01/06




投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com