

这个问题怎么解决呢?我们有这样的一个方法,因为UIP是要用户输入敏感数据。所以UIP上有相对的提示,这样的文本一定会出现在控页附近。第二个发现是,开发者写代码的时候,为了区分不同的控件肯定会有一个秘密,在这个里面也会包含。我们发现一些文本的价值,我们能不能通过文本分析,就能识别出来哪些控件要求输入隐私。对此,我们开发了一个程序叫做UIPicker,可以提供跟UIP相关的信息。识别它的控件和ID,这些跟控件相关的文本哪些是隐私的信息。主要的核心材料就是我们怎样构建一个文本,如果隐私文本不全,我们分析不出来。我们拿到一些UIP控件的文本,我们怎么设计一种方法来判别这个控件到底是不是在说一个跟隐私相关的信息。
最后,我们识别到了一些控件可能它跟隐私相关,但是它是不是要求用户输入隐私信息的控件呢?也不一定,有些控件也许是用来展示的。我们会分为四个环节,下面主要介绍一个思路。
第一个环节是预处理,我们拿到一个UI做代码分析,分析出所有在界面出现的文本,以及每个控件的秘密。第二个进行分词,对词语的分析。第三个做一些清洗,我们目前整个技术方案还是针对英文APP,中文的分词还没有做,所以我们会做一些英文的词。最后一步,提取每一个词语的词根,所有这些工作的目的是,因为开发者有这样的习惯,我们希望文本的表述尽量统一化,从而更好的做后面的工作。大量的使用自然语言的处理,对APP的识别包括对文本的描述。其次,我们拿到这些文本之后,我们需要知道哪些文本是跟隐私相关的。这个文本的集合来源在哪,人工定义的话可能会有一些偏见,我们怎么才能找到一种方法能够去找到一个比较全的集合呢。
我们是不是存在这样的问题,先定义几个词语,从初始的词语,慢慢地扩大,在某一个程度找到比较多的词语来去描述某些信息。这个想法比较好,但是怎么去做?怎么去推相关的词?我们发现在界面里面,一个界面上面可能会包含多种隐私文本相关的信息,比如说让输入用户名和密码,在账号设计上会包含多种隐私相关的文本,我们用这种自动化的方法去扩大初始。我们把初始的文本分为两半,一半在目前的分析认为这个界面包含一些隐私,另外不包含隐私。这个判断会有很大的不确定,因为这个数很小。但是基于几何分析,我们可以通过矩阵方法找到。我们针对这样的集合去挑选,如果有些词语经常在隐私界面出现,很少在不含隐私的界面出现,我们认为这个词语在很大的可能是在表述一种隐私的信息。我们通过迭代式的发展,可以一步一步扩大初始词语,最后得到比较全的隐私文本。最终对账户信息、地理位置信息、金融信息,我们通过七个词语,最后得到了228个词语,它们都是描述隐私文本。大部分是说跟隐私相关的信息。做完前两步之后,我们拿到一个APP,可以提取里面的UIP组件,以及UI相关的文本。下一步要做的是这个控件到底是不是在描述一种隐私信息,这是基于文本来识别这个控件到底有没有相关。
最后,我们用到了机器学习的方法,将我们识别到的228个隐私文本,针对每一个UI空间所包含的隐私控件,我们去判断它到底是不是隐私控件。核心去获得一个正向的集合,我们通过机器学习的方法去训练它。我们之前提到这种方案,通过识别这种UIP控件,它虽然不能很好地解决UIP控件识别精确和覆盖面的问题,但是它足以帮我们建立一个正向的结合,只要有这个属性一定是UIP控件。我们的一些控件,通过这样的机器学习可以训练出来一个模型,这个模型可以判断一个控件到底是不是跟用户输入的隐私相关。
在这一步中,我们并没有考虑到什么类型。有个问题是这个控件可能显示一些跟隐私文本相关的信息。举个例子,不是每一个隐私界面都要求用户输入,比如上面的单选框,是非常敏感的文本。都是一些非常隐私的文本,它也被我们识别为隐私控件,但是它不会要求输入任何隐私。下面的反而要求用户输入一些隐私,信用卡过期的时间。我们希望通过识别隐私的控件中,更加精确的识别哪些控件是要求我们输入隐私的。我们分析一下,没法通过控件类型识别隐私。我们也发现在APP中输入信息有很多途径,比如说下拉菜单也是一种方式,针对开发者的组件也是一种方式,我们通过类型去简单地把输入和非输入区分出来。
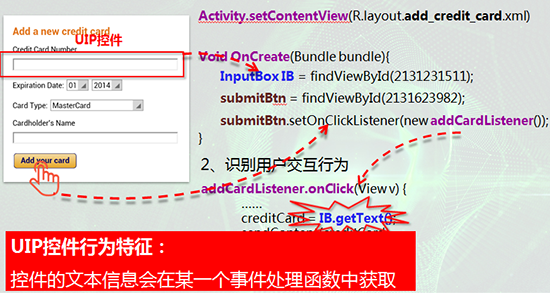
我们核心的思路是想基于这个程序,访问控件文本的行为它到底是不是在获取用户输入的一些文本。举个例子,左侧是一个输入信用卡的卡号界面,右边是对应的代码。我们分析后发现,这个控件是一个隐私相关控件,它在这个地方会得到应用。我们发现它有一个函数,我们发现在addcardlistener的框架里面,会有一个文本。我们获取的这样一种特征,作为识别一个空间到底是不是接收、输入的判断标准地从而比较好的将哪些只显示隐私文本的相关控件去除掉。
我大致系统的阐述了一下识别UIP控件的核心技术。后面设计了一个轻量UIP的保护系统,主要是TaintDroid系统。因为我们现在可以识别的一些UIP控件,只要控件的文本都是隐私文本,我们去跟踪程序如何使用它获取到的用户输入。我们发现如果当这个用户输入的数据通过不安全的网络通道发送出去的时候,我们认为这是一次有风险的行为。比如说具体的发现UIP信息,它通过不安全的通道发送信息,都会加大用户的风险。通过这样的系统,我们发现一些APP确实存在这样的风险和漏洞。比如说去哪儿网,它要求用户输入一个卡号的系统,是通过不安全的地址发现,我们也是反映给了去哪儿网。
下面介绍一下,看看这个技术到底它的效果怎么样。我们试验选取的数据大概是来自谷歌应用商城的17425个应用。最终我们发现在这17000多个应用中,有35个类别都会收集用户隐私。因为很多时候收集的数据是出于业务的需求,想衡量这类隐私是在APP当中非常普遍的,之前的方法没有办法对它进行保护的。我们发现在这几个案例中,针对用户账号这类的UIP数据,大量是社交,跟天气相关的应用。针对地理位置的隐私信息,天气、出行、搜秀这些APP当中比例会比较高。针对支付类的信息,我们认为这类信息的搜集很高,也是基本符合我们的认知常识的。我们也跟前面单纯的通过控件属性识别UIP的方法进行了对比,最终我们发现针对所有的这些敏感数据,我们能够比它多识别到两倍以上的控件,极大提高了覆盖范围。特别是针对这样一个地理位置信息。我们也发现了一些静态的控件,它也会显示用户输入的信息。因为可能这个控件的一些信息是通过前面的界面输入的,第二个界面也是让用户看一下,虽然不直接让用户输入,但这些界面也会包含一些隐私。这里面有25%都包含隐私数据。最终我们挑选了200个应用,在十个类别中,对精确率进行了衡量。我们发现最终取得的效果是非常好的,我们能够比较准确的识别到93.6%的UIP控件,针对所有可能的UIP控件找到了90.1%的水平。整个系统的性能还是非常好的。这个系统的性能也是一步一步提高。在这里,也要感谢我们团队对于我们整个的工作的支持。
最后总结一下今天的报告。主要的目的,我们首先分析出,移动平台目前这种隐私威胁是非常严峻的。在这个威胁中,输入类的隐私威胁是一个比较主流的地位。目前的方法很难有效的保护用户输入的隐私,核心困难在于它没有办法系统化的识别哪些隐私数据是用户输入的隐私。我们基于文本分析的方法是可以比较好的识别一些用户输入类的隐私,更好地保护这些隐私数据。好,谢谢大家!

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
移动平台用户隐私保护技术综述2016/01/08
高校移动平台迎来发展浪潮2014/09/16
移动平台 从移植到重新创造2013/02/22
对外经贸大学:基于微信企业号的高校移动平台设计与实现2016/12/05
隐私消亡的移动互联时代2016/05/30
掌上师大:以整体思维规划移动平台2012/11/14
平台设计:开放与简单的结合2012/11/14




投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com