

编者按:2015年8月,美国高等教育政策研究所(Institute for Higher Education Policy,IHEP)率先召集了一个由全国高等教育数据专家组成的工作组,来讨论推动一系列改进数据基础设施质量的新兴方案,为州和联邦的政策对话提供信息。作为成果的系列论文集——《展望21世纪的高等教育数据基础设施》提出了有针对性的建议,直接关心有关的技术、资源和政策考虑。《美国高等教育数据系统中的信息安全和隐私》为论文集中的一篇。从本期开始,本刊将连载相关内容。本文意在使读者了解信息安全和隐私的概念,以及国家高等教育数据基础设施中的技术等内容。
美国高等教育数据系统中的信息安全和隐私(二)
无论采用何种基础设施的架构,任何一个国家高等教育数据系统都含有一个大型数据集合。该集合的设计目的是提供有用和可靠的信息来反映高等教育中的学生成就和教育成效。“大数据”通常定义为:来自于多个来源的、大型的、复杂的电子数据集,以及这些数据集的事务数据(或元数据),因而相应地必须是“集成的、关联的或者共同分析的”。
数据集的安全和隐私关注点
由于数据的规模和复杂度,为了解决如何在这些数据集和支撑大数据集合的IT系统之间和之内维护信息安全和隐私的问题,必须要进行协同的探究。鉴于在全国范围内对学生平等和教育成效的疑问日益紧迫,而为了回应这些疑问又需要大量的数据,任何一个国家高等教育数据体系方案都受到了安全和隐私方面的关注。
对大数据的安全和隐私的高度关注点包括:数据量(采集到的数据的规模)、敏感性(采集到的数据的敏感性以及在不同系统之间潜在的敏感性差异)、访问权(为达到在更大数据集合中查询的目的而拥有多个大数据集合访问权的个人或实体)。
经过慎重的考量,利益相关者们可以在国家高等教育数据技术设施中实施全面的信息安全和隐私措施,以回应这些关注。
数据量
数据量涉及两个方面问题:第一个是大数据集合中的记录数量,无论是来源于学校、机构或者其他组织。第二个是采集到的关于每个人的数据项目数量。在大型数据集上实施的复杂分析,以及研究者从这些分析中分辨出的个人或群体的动向,其范围可能是非常广泛的。这种大型的数据集合,以及从中揭示出的洞察成果,经常会受到充满怀疑的目光的审视,尤其是当这些采集到的数据中含有可以识别出个人身份的信息时。对不同来源的数据匹配可以创造出新的数据集,其中包含可以识别出对应个人身份的充足信息;这种情况下,为了保护个人隐私,就要采取额外的保护措施。
在国家高等教育数据体系中,数据量两方面的问题都会涉及。数据可能取自于从体系中的多个实体(如学校、州和联邦机构)。另外,不同的实体(以及对应的IT系统)可能持有不同的个人数据项目。当合并这些数据项用于分析时,可能导致产生关于某个个人的详细描述,比任何单独一个实体本身能描述的都更加详细。
敏感性
数据的敏感性也是对大数据集合的一项关注,有两种互相区别但又密切相关的敏感性问题。
第一种问题是大数据集中可能含有不同类别数据的多种组合。普遍的数据分类包括可识别身份的数据、擦除身份的数据、匿名的数据和汇总的数据。因为数据的敏感性不同,不同类型的数据要有不同的安全和隐私保护措施。例如,可识别身份的数据要比匿名数据更加敏感。
第二种问题和第一种关系很近,不过仍然有细微差别,主要是在大数据集合中可识别身份的数据的使用方面。各种类型的可识别身份的数据并不是都有相同的敏感性。理解数据集中不同数据项的敏感性是至关重要的。某些数据项属于最高敏感性的数据类别,例如姓名和社会安全号Social Security Number,SSN)。因为它们仅凭单独一项数据就可以独立唯一识别某个人,或者它们被社会观念认为是高度敏感的。州和联邦法律,如《1974年家庭教育权利和隐私法案(FERPA)》或《1995年健康保险转移和问责法(HIPAA)》等,通常会要求对这些最敏感的数据项目进行保护。
另外一些数据项也可能被认为是敏感的,因为当它们组合在一起后很可能可以识别出唯一的个人。虽然其他的一些数据项仍然会被认为是可识别身份的数据,但是它们不太可能会被用来识别出唯一的个人。表1标出了不同类型的可识别个人身份的数据以及它们的敏感性。
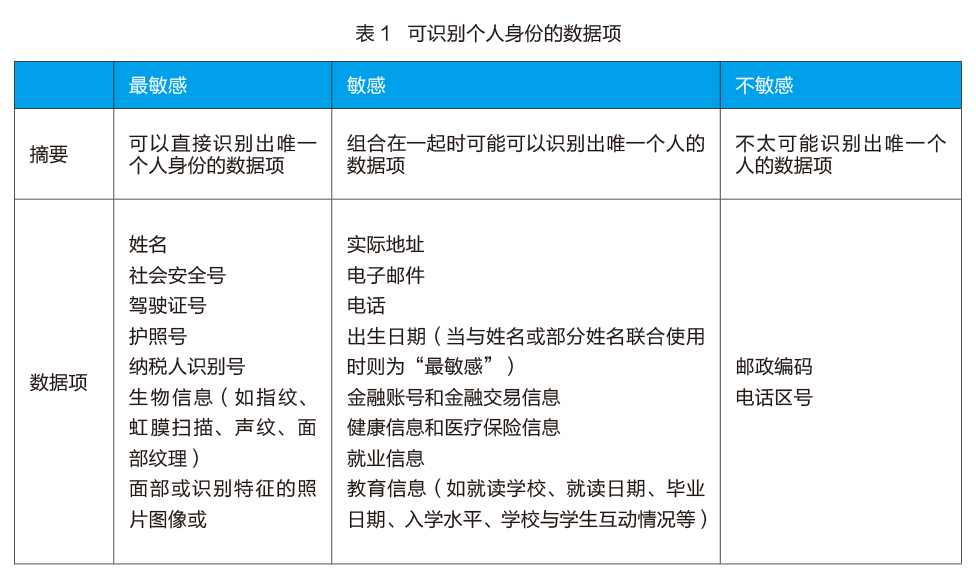
在大数据集合中,不同类别的数据和不同的可识别身份的数据项进行组合,对数据的查询所返回的结果中包含的数据项也具有不同的敏感度。此时,对这些查询的结果必须要进行安全保护,而且保护的方式应当与其中含有的最高敏感度的数据的保护方式相一致。这样的要求对于单点数据系统和多点数据系统都是一项挑战。
在国家高等教育数据体系中,IT从业者要采取两种方式来应对敏感性挑战。首先,参与体系的实体必须在其所控制的IT系统中实施适当的安全和隐私保护。这表明,要确保那些系统对其所采集到的数据的保护级别符合系统保存的最敏感的数据项的要求。这就意味着,即便是同一个实体的不同系统也可能有不同的保护级别。其次,除了单个IT系统级别的保护以外,在国家体系中的所有实体要联合协作,以确保在实体之间和体系之内共享的数据受到妥善的保护,即任何分析在向最终用户报告数据的终端点上,数据的保护水平达到其中所包含的最敏感的数据项目的要求。
访问权
采集和存储的个人信息的访问范围十分广泛,尤其是通过互联网和个人移动设备时,访问范围几乎是全球的。几乎所有的大数据集合都设计成为供多个实体、从多个地点、为了多种目的而进行访问。对访问权的关切一般分为两类:一是针对无合法访问权的外部角色,对数据进行保护;二是针对有合法访问权的人员等内部角色,在出现故意超出事先批准的授权范围、通过未批准的设备、或偶然错误地披露数据的情况时,对数据进行保护。国家高等教育数据基础设施中,多个IT系统可以互相链接,来自多个所有者的数据集在共享系统中组合,而且有访问数据的人数众多。因此,信息安全控制不仅有必要防护数据免于外部侵入,而且有必要实施控制合法人员的访问政策。
基础设施的数据安全保护
对于一个高等教育数据系统和构成整个体系的底层IT系统而言,不存在信息安全和隐私保护一刀切的设计公式,可以用来确保在其中流动的所有数据的安全和隐私。在《展望21世纪的高等教育数据基础设施》中所提出的所有方案中,每一个都提出了信息安全和隐私方面的、自身特有的一组技术挑战,这需要根据解决方案中所采用的底层技术和流程逐一加以应对。因此,采用全面的解决途径是必不可少的,即乐于采用最佳实践、降低整体风险降低、实施数据保护,以及实现整个体系的透明、问责和信任。
信息安全保护
一些信息安全标准和最佳实践的资源是现成的。几乎所有的标准都是基于同一个概念,即良好的信息安全实践是在试图降低风险和保护数据。此处的风险指的是某个威胁利用某个漏洞产生损害的可能性。例如,某个恶意的黑客(威胁)猜出了某个用户的IT系统弱密码(漏洞),然后从数据库中盗窃出了数据并随后利用数据伤害了某人(身份窃取)。风险实现的可能性以及风险实现的损害影响因环境不同而不同。并不是所有的风险或者漏洞都需要同样级别的关注,而且大多数机构并不拥有尝试消除所有安全信息风险的资源。通过风险并评估其相对严重性,是国家高等教育数据基础设施中必不可少的组成部分。
大多数风险评估方法包括了四个基本的风险评估步骤:一是对评估了解范围内的数据资产和数据开列清单;二是确定这些资产和数据所面临的威胁和漏洞(统称风险);三是对特定风险发生的可能性和潜在损失进行分类;四是记录下为应对所确定出的风险所需的控制点。
风险评估的主要成果是,根据可能性和影响程度(如低、中、高)矩阵识别出IT资产和数据的风险,并且制订计划方案,用对底层组织而言切实可行的方式应对风险。组织根据其风险容忍度,可以选择应对不同类型的风险:(1)最有可能发生的风险;(2)一旦发生将可能造成最严重损失的风险;(3)从资源角度来看最容易应对的风险;(4)同时满足上述某些条件的风险。
IT从业者在识别出风险并进行评估后,可以采取信息安全控制措施加以解决。评估风险和实施信息安全控制措施的最终目的是保护组织的IT资源和其中的数据。为了恰当地应对风险,可以采用信息安全领域中的以下通用措施:
(1)资产管理的关注焦点是如何从创建或获得到销毁的全生命周期中,管理IT系统及其中的数据。
(2)身份认证、鉴权和访问控制涉及如何识别授权用户的身份、鉴权(证明其身份)以及被授予IT系统及其中数据的访问权。
(3)运行安全指的是IT系统及其中的数据是如何操作,如何防范威胁,以及如何测试漏洞的。恶意软件保护、系统日志和监控、数据备份以及漏洞管理都包含在这个大类中。
(4)通信安全指的是当数据在网络或者IT系统中移动,包括在一个组织内部或多个组织之间移动的情况下,IT系统及其中的数据是如何受到保护的。
(5)物理环境安全涉及IT系统及其中的数据如何防范物理丢失、机械故障和环境破坏。包括如何通过防范如下风险来保护IT系统:盗窃或丢失;自然灾害,例如火灾、洪水、台风;蓄意破坏;电源中断或其他机械故障。
(6)事件响应、业务持续和灾难恢复指的是当出现涉及IT系统及其中数据的事件时组织如何响应,以及如何从这些事件中恢复。组织必须为一些不同类型的事件(如恶意攻击、自然灾害、断续的网络连接等)建立响应和恢复规程。
(7)培训和意识涉及组织如何培训雇员和其他IT用户,并且传播关于如何推动良好信息安全实践的意识。培训和意识非常重要,因为即使有最好的意愿,雇员和其他可信个人也有可能会无意中损害IT系统及其中数据的安全。

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
美国高教信息化:从管理系统向环境迈进2018/05/28
美国国家安全教育2018/04/10
美国部分大学怎样开设通识选修课2018/04/10
美国马里兰州一高中发生枪击案枪手死亡两学生受伤2018/03/21
美国老教师在校内开枪 “带枪上班”靠谱吗?2018/03/02
美国肯塔基州一中学发生枪击案造成2死17伤2018/01/24
2017,美国高等教育回望2018/01/16




投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com